ABSTRAK
Proporsi orang lanjut usia dalam total populasi dunia diperkirakan akan meningkat. Penyakit tulang lebih umum terjadi pada orang lanjut usia; oleh karena itu, jumlah pasien dengan penyakit tersebut diperkirakan akan meningkat di seluruh dunia. Tulang buatan merupakan biomaterial yang digunakan dalam pengobatan penyakit tulang. Tulang buatan dengan tingkat pembentukan tulang yang tinggi diinginkan; namun, hasil implantasi tulang buatan bervariasi. Ada juga masalah etika yang terkait dengan percobaan pada hewan. Tujuan kami dalam penelitian ini adalah untuk memprediksi variasi dalam tingkat pembentukan tulang. Kami membuat beberapa sub-himpunan data dan membangun model pembelajaran mesin untuk memprediksi variasi dalam tingkat pembentukan tulang dengan mempertimbangkan hasil dari beberapa pengukuran. Kami juga mengusulkan metrik, divergensi Jensen–Shannon (JS), untuk mengevaluasi keakuratan model dalam memprediksi variasi. Kami menguji validitas divergensi JS dengan membandingkan kombinasi variabel penjelas. Selain itu, kami menemukan kombinasi variabel penjelas yang optimal untuk membangun model dengan akurasi prediktif yang tinggi. Kami berharap bahwa prediksi variasi akan berguna untuk meningkatkan pengembangan praktis bahan dan obat-obatan, seperti tulang buatan, yang memerlukan efek yang stabil, terlepas dari individunya.
1 Pendahuluan
Proporsi penduduk lanjut usia terhadap total populasi dunia telah meningkat dari 5,1% pada tahun 1950 menjadi 9,3% pada tahun 2020, dan diperkirakan akan terus meningkat [ 1 ]. Dengan bertambahnya harapan hidup rata-rata, diperkirakan jutaan orang akan menderita penyakit yang menyerang tulang di banyak negara [ 2 ]. Oleh karena itu, diperkirakan jumlah penyakit tulang, seperti pengeroposan tulang, akan meningkat di seluruh dunia.
Sebagian besar terapi untuk defek tulang didasarkan pada autograft atau allograft; namun, terapi ini memiliki kekurangan, seperti sumber pasokan yang terbatas dan risiko reaksi imun. Dengan demikian, tulang buatan, khususnya jenis yang meningkatkan regenerasi tulang, saat ini menjadi fokus perhatian [ 3 ]. Misalnya, hidroksiapatit (Ca 10 (PO 4 ) 6 (OH) 2 ; HAp) dan β-trikalsium fosfat (β-Ca 3 (PO 4 ) 2 ; β-TCP) diharapkan berguna dalam kedokteran gigi dan ortopedi karena strukturnya mirip dengan jaringan tulang manusia [ 4 ]. Para peneliti telah menunjukkan bahwa bahan yang sangat aktif secara biologis dapat disintesis dengan menggabungkan silikon, yang diperlukan untuk pertumbuhan tulang [ 5 ]. Optimalisasi parameter fisikokimia tulang buatan [ 6 ] juga sedang diteliti. Keramik HAp saat ini digunakan sebagai tulang buatan dalam pengaturan klinis; Namun, cangkok tulang autologus menghasilkan hasil yang lebih baik daripada cangkok tulang buatan [ 7 ].
Laju pembentukan tulang merupakan salah satu sifat terpenting tulang buatan dan diukur menggunakan implantasi pada hewan. Eksperimen hewan semacam itu diperlukan untuk pengembangan tulang buatan; namun, ada dua masalah: pertama, laju pembentukan tulang pada hewan percobaan tidak dapat diukur hingga beberapa bulan setelah implantasi, dan kedua, pengorbanan hewan harus dihindari dari sudut pandang etika [ 8 ]. Untuk mengatasi masalah ini, dalam penelitian sebelumnya, para peneliti membangun model pembelajaran mesin dua tahap untuk memprediksi laju pembentukan tulang dari tulang buatan [ 9 ]. Model pertama memprediksi sifat fisik dari kondisi eksperimen, dan model kedua memprediksi laju pembentukan tulang dari tulang buatan dari data spektral dan sifat fisik yang diprediksi menggunakan model pertama. Dalam kumpulan data yang digunakan dalam penelitian sebelumnya [ 9 ] dengan pembelajaran mesin, terdapat beberapa hasil untuk laju pembentukan tulang untuk setiap sampel atau tulang buatan karena eksperimen implantasi dilakukan pada beberapa individu. Nilai rata-rata dari beberapa hasil untuk laju pembentukan tulang diproses sebagai nilai representatif dan model pembelajaran mesin dibangun. Meskipun model dapat memprediksi laju pembentukan tulang, model tersebut tidak dapat memprediksi bagaimana laju konformasi tulang akan bervariasi untuk setiap tulang buatan. Meskipun tingkat pembentukan tulang yang tinggi sangat penting dalam mengevaluasi tulang buatan, sama pentingnya bahwa hasil tingkat pembentukan tulang tersebut stabil, yang berarti hanya ada sedikit variasi. Oleh karena itu, merupakan masalah dalam desain tulang buatan untuk memprediksi hanya rata-rata tingkat pembentukan tulang buatan. Selain itu, tidak ada metode untuk mengevaluasi akurasi prediktif suatu model ketika ada beberapa nilai terukur dan nilai estimasi.
Oleh karena itu, tujuan kami adalah mengembangkan kerangka kerja pembelajaran mesin yang mampu memprediksi tidak hanya rata-rata tetapi juga variasi dalam laju pembentukan tulang dari tulang buatan, menggunakan pemodelan ansambel dan metrik kesamaan distribusi. Pendekatan ini berupaya mendukung desain biomaterial yang dapat direproduksi dan mengurangi ketergantungan pada pengujian hewan. Kami menyiapkan sejumlah sub-himpunan data dengan mengambil sampel secara acak dari suatu himpunan data, dan membangun model regresi untuk setiap sub-himpunan data. Ketika 100 model dibangun, misalnya, 100 model yang dibangun menghasilkan 100 nilai laju pembentukan tulang untuk setiap sampel, yang memungkinkan untuk merepresentasikan distribusi laju pembentukan tulang. Selain itu, kami mengusulkan metrik berdasarkan divergensi Jensen–Shannon (JS) untuk membandingkan distribusi secara kuantitatif.
2 Kebaruan karya ini
Strategi prediksi ensemble berbasis sub-dataset dikembangkan untuk memodelkan dan mengukur variabilitas dalam laju pembentukan tulang buatan, yang belum dibahas dalam penelitian sebelumnya.
Aplikasi baru divergensi JS diusulkan untuk mengevaluasi kinerja prediktif untuk keluaran distribusional—menawarkan metrik pelengkap untuk r 2 konvensional .
Metode yang diusulkan diterapkan di bidang biomaterial, khususnya untuk tulang buatan, di mana variabilitas antar hewan menimbulkan masalah serius untuk eksperimen yang etis dan praktis.
3 Metode
3.1 Kumpulan Data
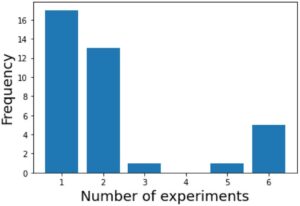
Dataset kami berisi 38 jenis tulang buatan yang disintesis menggunakan dua metode: proses basah [ 7 ] dan metode presipitasi homogen [ 10 ]. Fitur-fiturnya adalah kondisi eksperimen, kondisi eksperimen hewan, sifat material, spektroskopi inframerah transformasi Fourier (FT-IR) dan data spektral difraksi sinar-X (XRD), dan gambar mikroskop elektron pemindaian (SEM). Kondisi eksperimen meliputi jumlah reagen yang digunakan dalam sintesis, suhu pemanasan, jumlah manik karbon yang ditambahkan, serta hewan yang digunakan dalam percobaan hewan dan waktu yang dibutuhkan. Sifat material meliputi variabel yang diukur dalam waktu yang relatif singkat, seperti kepadatan relatif dan kekuatan tekan. Ini adalah sifat yang diketahui mempengaruhi pembentukan tulang ketika dikontrol [ 11 , 12 ]. FT-IR dan XRD digunakan untuk mengidentifikasi gugus fungsi dan fase kristal [ 13 ]. Selain itu, gambar SEM sering digunakan untuk menganalisis struktur tulang buatan [ 14 ]. Ada satu atau beberapa hasil untuk laju pembentukan tulang untuk setiap tulang buatan karena kami melakukan percobaan implantasi pada beberapa individu. Seperti yang ditunjukkan pada Gambar 1 , 17 jenis tulang buatan dilakukan hanya pada satu percobaan hewan dan yang lainnya dilakukan pada beberapa percobaan hewan. Selain itu, seperti yang ditunjukkan pada Gambar 2 , beberapa laju pembentukan tulang untuk setiap tulang buatan bervariasi.

3.2 Sub-Dataset
Bila terdapat beberapa nilai dalam variabel objektif y untuk setiap sampel, kami biasanya menggunakan nilai rata-rata y dalam konstruksi model umum. Akan tetapi, model yang mempertimbangkan variasi y tidak dapat dibangun dengan nilai rata-rata. Oleh karena itu, kami menyiapkan banyak sub-himpunan data dengan memilih satu nilai y secara acak dari setiap sampel. Dalam sub-himpunan data ini, variabel penjelas X sama untuk setiap sampel.
3.3 Konstruksi Model
Kami membangun model pembelajaran mesin antara X dan y untuk setiap sub-himpunan data, yang menghasilkan jumlah model yang sama dengan sub-himpunan data. Saat membangun model, kami mempertimbangkan beberapa metode regresi dan memilih metode terbaik untuk setiap sub-himpunan data. Memasukkan nilai X untuk sampel ke dalam model ini menghasilkan jumlah nilai estimasi yang sama dengan model, yang memungkinkan kami untuk memprediksi variabilitas y .
3.4 Divergensi Jensen–Shannon
Sampel tersebut memiliki beberapa nilai terukur dan beberapa nilai estimasi. Semakin dekat jarak antara distribusi nilai terukur dan nilai estimasi, semakin baik hasil prediksi. Oleh karena itu, kami memperkenalkan divergensi JS sebagai metrik untuk jarak antara distribusi. Divergensi JS dihitung dari dua persamaan berikut:
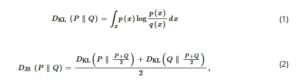
di mana p ( x ) dan q ( x ) adalah distribusi probabilitas, D KL menunjukkan divergensi Kullback–Leibler, dan D JS menunjukkan divergensi JS. Persamaan ( 1 ) adalah rumus untuk menghitung D KL , yang menghitung kesamaan distribusi probabilitas p ( x ) dan q ( x ). Persamaan ( 2 ) adalah rumus untuk menghitung D JS yang memberikan simetri pada D KL dengan membuat p ( x ) dan q ( x ) dapat dipertukarkan. Nilai metrik ini lebih besar dari atau sama dengan 0. Semakin dekat ke 0, semakin dekat jarak antara dua distribusi probabilitas. Untuk mengevaluasi hasil konstruksi model untuk indikator ini, kami mengasumsikan bahwa nilai aktual dan estimasi sampel mengikuti distribusi normal.
4 Hasil dan Pembahasan
Kami menggunakan kondisi sintesis tulang buatan, kondisi percobaan pada hewan, dan sifat fisik untuk semua konstruksi model. Kami menggunakan delapan kombinasi dari tiga jenis variabel, gambar FT-IR, XRD, dan SEM, sebagai X dalam metode A–H. Seperti yang ditunjukkan pada Tabel 1 , pada masing-masing metode, variabel dengan 〇 digunakan dan variabel dengan × tidak digunakan dalam pemodelan X.
| Metode | FT-IR | Analisis sinar-X | SEJARAH | JS Bahasa Inggris | r 2 |
|---|---|---|---|---|---|
| A | Bahasa Indonesia: | Bahasa Indonesia: | Bahasa Indonesia: | 0.726 | -0,496 |
| B | “ | Bahasa Indonesia: | Bahasa Indonesia: | 0,370 tahun | 0,579 tahun |
| C | Bahasa Indonesia: | “ | Bahasa Indonesia: | 0.383 | 0.500 |
| D | Bahasa Indonesia: | Bahasa Indonesia: | “ | 0.707 | -0,501 |
| Bahasa Inggris | “ | “ | Bahasa Indonesia: | 0.298 | 0,562 tahun |
| F | “ | Bahasa Indonesia: | “ | 0.334 | 0.439 |
| G | Bahasa Indonesia: | “ | “ | 0.383 | 0.500 |
| H | “ | “ | “ | 0.361 | 0,537 tahun |
Singkatan: FT-IR, spektroskopi inframerah transformasi Fourier; XRD, difraksi sinar-X; SEM, mikroskop elektron pemindaian.
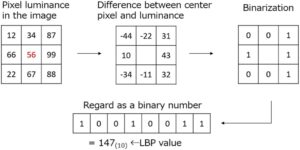
Untuk spektrum FT-IR dan XRD, kami memilih bilangan gelombang dan sudut difraksi yang terkait dengan HAp dan β-TCP, yang kami gunakan sebagai bahan, dan menggunakan intensitas pada bilangan gelombang tersebut sebagai X. Untuk gambar SEM, kami mengubah kecerahan pada setiap piksel gambar menjadi pola biner lokal (LBP) dan menggunakan frekuensi nilai tersebut sebagai nilai fitur. Selain itu, kami mengubah luminansi pada setiap piksel gambar menjadi LBP dan menggunakan frekuensi nilai tersebut sebagai fitur. Seperti yang ditunjukkan pada Gambar 3 , untuk piksel tertentu, kami menghitung perbedaan luminansi dari piksel di sekitarnya. Kami mengbinerisasi nilai-nilai ini sehingga menjadi 0 jika negatif dan 1 jika positif. Kami menganggap piksel biner yang diratakan sebagai bilangan biner. Kami mengubah bilangan biner ini menjadi bilangan desimal dan menganggapnya sebagai nilai LBP untuk piksel tersebut. Karena LBP menggunakan nilai relatif, ia lebih sensitif terhadap perubahan dalam bayangan gambar daripada luminansi.
Kami menetapkan jumlah sub-dataset menjadi 100 dan membangun model untuk setiap sub-dataset. Metode analisis regresi yang kami gunakan dalam konstruksi model adalah kuadrat terkecil biasa [ 15 ], regresi kuadrat terkecil parsial [ 16 ], regresi ridge [ 17 ], operator penyusutan dan pemilihan absolut terkecil [ 17 ], jaring elastis [ 17 ], regresi vektor pendukung linier [18] untuk metode regresi linier dan regresi proses Gaussian [ 19 ], regresi vektor pendukung nonlinier [ 18 ], pohon keputusan [ 20 ], hutan acak [ 21 ], pohon keputusan peningkatan gradien [ 22 ], peningkatan gradien ekstrem [ 23 ], dan model peningkatan gradien ringan [ 23 ] untuk metode regresi nonlinier. Kami mengevaluasi kemampuan prediktif setiap model menggunakan validasi silang ganda [ 24 ] (lipatan dalam: 5, lipatan luar: 10). Kami menghitung D JS untuk setiap material dengan asumsi bahwa laju pembentukan tulang dari tulang buatan mengikuti distribusi normal. Untuk sampel dengan satu atau dua nilai terukur untuk laju pembentukan tulang, kami mengganti simpangan baku untuk menghitung distribusi rata-rata simpangan baku sampel dengan tiga atau lebih nilai terukur.
Metode A mencapai akurasi terburuk dalam D JS dan terburuk kedua dalam r 2 dibandingkan dengan semua metode lainnya. Metode B dan C meningkatkan akurasi atas metode A dengan menambahkan variabel spektrum. Sebaliknya, metode D, yang menggunakan fitur gambar SEM, tidak mencapai peningkatan akurasi yang signifikan. Ini mungkin karena kami menggunakan regresi campuran Gaussian iteratif [ 23 ] untuk mengisi variabel yang hilang dalam gambar SEM, tetapi akurasinya tidak terlalu tinggi. Menggabungkan beberapa jenis variabel menghasilkan peningkatan akurasi untuk semua metode. Metode E memiliki nilai terbaik untuk D JS dan r 2 . Dibandingkan dengan Metode E, Metode F memiliki D JS yang lebih unggul dan r 2 yang lebih rendah . Metode B memiliki r 2 yang lebih unggul tetapi D JS yang lebih rendah . Lebih jauh lagi, Metode D memiliki nilai yang lebih buruk untuk kedua metrik. Kami membandingkan empat metode, yaitu, E, F, B dan D dengan tren yang berbeda dalam dua metrik, untuk mengonfirmasi validitas D JS sebagai metrik evaluasi.
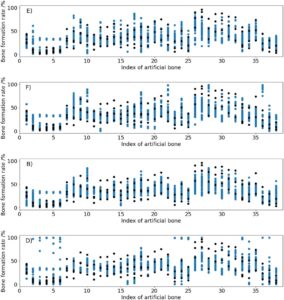
Plot rata-rata nilai terukur dan terestimasi dari metode B, D, E, dan F ditunjukkan pada Gambar 4 , dan plot lainnya ditunjukkan pada Gambar S1 , dengan persegi panjang ditambahkan ke plot dengan panjang horizontal sebagai variasi nilai terukur dan panjang vertikal sebagai variasi nilai terestimasi. Semakin dekat plot ke diagonal, semakin baik prediksinya. Selain itu, semakin dekat persegi panjang ke persegi, semakin baik prediksi variabilitas nilai terestimasi. Gambar 4 , yang hanya memplot nilai rata-ratanya, menunjukkan bahwa plot metode B dan E lebih dekat ke diagonal, sedangkan plot metode D dan F lebih jauh dari diagonal. Gambar dengan persegi panjang menunjukkan bahwa persegi panjang yang dekat dengan persegi lebih umum untuk metode E dan F. Sebaliknya, persegi panjang sempit sedikit lebih umum untuk metode B daripada metode E dan F. Selain itu, metode D memiliki persegi panjang yang jauh lebih memanjang. Hasil ini menunjukkan bahwa metode E dan F lebih unggul dalam memprediksi variasi, sedangkan metode B dan D lebih rendah. Kami membandingkan hasil ini dengan hasil pada Tabel 1. Kami menghitung r2 dari rata-rata nilai terukur dan terprediksi, sehingga membuat metrik bergantung pada rata-rata nilai. Sebaliknya, kami menghitung D JS dari distribusi normal laju pembentukan tulang, sehingga membuat metrik ini bergantung pada rata-rata dan deviasi standar laju pembentukan tulang. Karena metode B dan E, yang memiliki plot rata-rata yang lebih unggul, juga memiliki nilai r2 yang lebih unggul , r2 adalah metrik yang cocok untuk evaluasi nilai rata-rata. D JS juga merupakan metrik yang baik untuk mengevaluasi variasi karena nilai D JS sangat baik dalam metode E dan F, di mana plot persegi panjang lebih unggul.

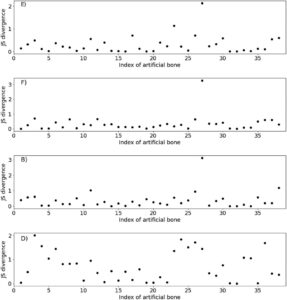
Nilai estimasi berwarna biru dan nilai terukur berwarna hitam diplot berdampingan untuk setiap tulang buatan untuk metode E, F, B, dan D pada Gambar 5 , dan plot lainnya ada pada Gambar S2 . Selain itu, D JS untuk setiap material untuk metode E, F, B, dan D diplot pada Gambar 6 , dan plot lainnya ada pada Gambar S3 . Misalnya, untuk metode E pada Gambar 5 , variasi antara nilai estimasi dan prediksi berdekatan untuk material 1, tetapi variasi berjauhan untuk material 27. Dengan mempertimbangkan D JS material ini pada Gambar 6 , D JS material 1 rendah dan D JS material 27 tinggi. Dari hasil ini, metrik D JS mengonfirmasi keakuratan prediksi variasi untuk setiap material. Gambar 5 juga menunjukkan bahwa metode terbaik, E, cenderung kurang akurat dalam memprediksi material dengan nilai terukur tinggi. Kami mengganti simpangan baku bahan dengan tingkat pembentukan tulang yang tinggi dengan rata-rata simpangan baku sampel dengan tiga atau lebih nilai terukur karena jumlah nilai terukurnya kecil. Oleh karena itu, fakta bahwa variasi terukur yang sebenarnya bukanlah variasi bahan asli mungkin telah menyebabkan penurunan akurasi prediksi variasi.