
Abstrak
LATAR BELAKANG
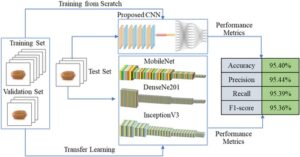
Visi komputer dan penggunaan solusi berbasis gambar semakin diminati sebagai metode penilaian makanan non-destruktif karena rendahnya biaya peralatan komputasi. Penelitian yang dilakukan pada pengembangan model klasifikasi gandum didasarkan pada data yang terbatas dan jumlah kelas yang lebih sedikit dibandingkan dengan ketersediaan varietas gandum. Untuk menilai penerapan model jaringan saraf konvolusional (CNN), penelitian ini menyiapkan gambar multi-tampilan dari 124 varietas gandum. Dengan menggunakan metode pembelajaran mendalam (DL), model CNN empat lapis dikembangkan dari awal, dan arsitektur populer, DenseNet201, MobileNet, dan InceptionV3 dilatih menggunakan pembelajaran transfer.
HASIL
Model CNN yang diusulkan, yaitu DenseNet201, MobileNet, dan InceptionV3 masing-masing mencapai akurasi klasifikasi sebesar 95,40%, 92,41%, 90,54%, dan 83,47%, dan model-model tersebut terbukti menjanjikan dan berhasil. Meskipun terdapat tantangan terkait dengan tuntutan sumber daya komputasi yang tinggi, model CNN yang baru diusulkan mengungguli model yang telah dilatih sebelumnya. Dapat disimpulkan bahwa kumpulan data multi-tampilan dan gambar besar berkontribusi secara signifikan terhadap keberhasilan model dalam mencapai akurasi yang menjanjikan dalam tugas yang menantang untuk mengklasifikasikan 124 varietas gandum.
KESIMPULAN
Studi saat ini merekomendasikan penyempurnaan lebih lanjut dari hiperparameter untuk meningkatkan akurasi model CNN yang diusulkan dan untuk mengidentifikasi konfigurasi yang lebih baik. Selain itu, model populer lainnya harus dievaluasi. Selain itu, dengan membekukan lapisan awal tertentu, penyempurnaan harus dilakukan untuk memaksimalkan akurasi. Selain itu, kumpulan data gambar yang digunakan akan tersedia untuk umum agar para peneliti dapat menemukan metodologi baru untuk mengklasifikasikan varietas gandum. © 2025 Penulis. Jurnal Ilmu Pangan dan Pertanian diterbitkan oleh John Wiley & Sons Ltd atas nama Society of Chemical Industry.
PERKENALAN
Gandum dianggap sebagai sumber energi utama (karbohidrat). Gandum menempati tempat sentral dalam nutrisi manusia, menyediakan 20% protein dan kalori harian. Namun, gandum juga mengandung sejumlah besar nutrisi penting lainnya, serat dan komponen minor termasuk lipid, vitamin, mineral dan fitokimia, yang dapat berkontribusi pada pola makan yang sehat. 1 Untuk memastikan keberlanjutan produksi gandum, dalam beberapa dekade terakhir, banyak transformasi teknologi telah terjadi dalam produksi pertanian, sehingga membuat sektor ini lebih maju dan berbasis teknologi. Teknologi modern telah menyediakan masyarakat manusia fasilitas dan kapasitas untuk menghasilkan makanan yang cukup untuk memenuhi permintaan pangan global. Untuk memenuhi kebutuhan pangan di seluruh belahan dunia, orang telah membudidayakan sekitar 30.000 varietas gandum, tetapi terutama gandum roti heksaploid ( Triticum aestivum ), yang menyumbang sekitar 95% dari produksi gandum dunia. 2
Untuk mewujudkan produksi dalam skala besar tersebut, diperlukan perhatian terhadap faktor-faktor penting di berbagai tahap pertanian, mulai dari tahap produksi, informasi tentang tanah, prakiraan cuaca terutama hujan, varietas tanaman, potensi hasil panen, dan penggunaan pestisida dan herbisida sangatlah penting. Selain itu, pada tahap pengolahan, kurangnya teknologi pasca panen yang tepat dan tren pasar berdampak negatif terhadap efisiensi dan potensi pertanian secara keseluruhan serta menyebabkan kerugian besar dan munculnya masalah yang tidak terduga di samping permintaan pangan yang terus meningkat sebagai akibat dari peningkatan populasi global. 3
Dengan demikian, memiliki data dan informasi tentang semua aspek pertanian membantu para petani untuk membuat keputusan berdasarkan data guna meningkatkan produktivitas. Inovasi terkait data seperti Internet of Things (IoT), yang didukung oleh pembelajaran mesin (ML), pembelajaran mendalam, dan komputasi awan, memiliki potensi untuk memperoleh informasi dan memprosesnya sesuai kebutuhan mereka untuk meningkatkan kualitas dan pada akhirnya meningkatkan keuntungan pertanian. 4 Teknik ML pada dasarnya terdiri dari prosedur untuk belajar dari pengalaman atau data pelatihan guna melakukan tugas tertentu. Data yang digunakan untuk melatih model berisi serangkaian contoh. Karena keuntungan dari biaya peralatan dan komputasi yang rendah, serta meningkatnya permintaan akan teknik penilaian makanan yang tidak merusak, visi mesin dan solusi berbasis gambar semakin berkembang pesat. 5 Visi komputer atau visi mesin adalah mekanisme berbasis kecerdasan buatan (AI) yang membekali komputer dengan kemampuan visual seperti manusia untuk merasakan dan menafsirkan kondisi, mengenali objek, dan membuat keputusan dengan bantuan berbagai algoritme. 6 Kemampuan untuk mengekstrak informasi yang bermakna dari gambar dan video serta mengenali pola tersembunyi adalah pendekatan yang memungkinkan mesin untuk melakukan tugas yang memerlukan kecerdasan manusia dan pekerjaan manual.
Selain itu, penerapan visi mesin dalam kemajuan pertanian telah membuka perspektif baru untuk mengatasi tantangan pertanian. Meskipun visi mesin menghadapi banyak tantangan, keunggulannya lebih besar daripada pendekatan konvensional. 7 Penerapan terpadu algoritma visi mesin dan berbagai metode pembangkitan parameter seperti sensor, citra, dan spektroskopi telah banyak digunakan untuk mengatasi tantangan pertanian terkait penilaian pangan. 8 Penerapan pendekatan yang disebutkan di atas memungkinkan praktisi untuk menghasilkan data deskriptif, mengembangkan model, dan akhirnya mengotomatiskan aktivitas yang berulang dan membosankan untuk meningkatkan efisiensi teknis dan ekonomi keseluruhan suatu sistem. 9 Dalam konteks produksi gandum, pelatihan dan pengembangan model AI khusus untuk klasifikasi varietas gandum penting karena memungkinkan identifikasi dan pengenalan varietas yang akurat, menjaga alokasi sumber daya yang optimal, dan praktik pengelolaan tanaman yang lebih baik. Seiring dengan terus berlanjutnya pelepasan varietas gandum baru, pentingnya identifikasi dan klasifikasi yang tepat menjadi semakin penting. Di Turki, misalnya, 617 varietas gandum telah dirilis sejak yang pertama pada tahun 1928. Dari tahun 2016 hingga 2020, Turki memimpin dalam merilis varietas gandum terbanyak, diikuti oleh Inggris, Hongaria, dan Iran. 10 Hal ini menggarisbawahi upaya berkelanjutan untuk meningkatkan dan memperluas produksi gandum secara global. Salah satu keputusan utama dalam pertanian adalah memilih varietas gandum yang tepat. Untuk mencapai hasil panen tertinggi, sangat penting untuk mengidentifikasi setiap varietas yang akan dibudidayakan. Di sinilah model pembelajaran mendalam (DL) dapat memainkan peran penting karena dapat mengidentifikasi berbagai varietas gandum dengan cepat dan tepat. Setiap varietas gandum harus diidentifikasi terlebih dahulu dan kemudian dievaluasi berdasarkan faktor-faktor yang sesuai untuk memilih varietas yang paling sesuai untuk kondisi tertentu. 11
Salah satu algoritma pembelajaran mendalam yang populer yang diterapkan dalam mengklasifikasikan varietas gabah adalah jaringan saraf konvolusional (CNN). CNN adalah algoritma pembelajaran mendalam yang menggunakan gambar sebagai data masukan. Sebagai bagian dari pembelajaran mendalam, CNN termasuk dalam jaringan saraf buatan. Jaringan tersebut mengklasifikasikan gambar dengan memanfaatkan fitur-fiturnya. Alasan CNN memerlukan praproses yang lebih sedikit dibandingkan dengan algoritma klasifikasi lainnya adalah kemampuannya untuk mempelajari filter. CNN tersusun atas lapisan konvolusional, unit non-linier, lapisan penggabungan, dan lapisan yang terhubung penuh. Gambar yang diproses melalui lapisan-lapisan ini menjalani berbagai operasi agar sesuai dengan model pembelajaran mendalam. Dalam masalah klasifikasi, lapisan konvolusional, unit non-linier, dan lapisan penggabungan bersama-sama membentuk lapisan ekstraksi fitur untuk mengekstraksi fitur, sedangkan lapisan yang terhubung penuh membentuk lapisan klasifikasi. Lapisan penggabungan adalah proses seleksi yang mengurangi dimensi fitur yang diekstraksi sambil mempertahankan informasi penting. 12 Rangkaian algoritma ini berfungsi sebagai ekstraktor fitur yang canggih, yang mampu digunakan untuk tugas-tugas tingkat lanjut seperti klasifikasi gambar, deteksi objek, segmentasi gambar, dan masih banyak lagi. Dibandingkan dengan model pembelajaran mesin tradisional, CNN sangat cocok untuk tugas klasifikasi berbasis gambar karena kemampuannya untuk secara otomatis mempelajari fitur spasial hierarkis, seperti tepi, tekstur, dan pola, langsung dari data piksel mentah. Sebaliknya, model klasik biasanya bergantung pada ekstraksi dan rekayasa fitur manual, yang meningkatkan kompleksitas pengembangan model dan dapat membatasi kinerja generalisasi.
Upaya yang ditujukan untuk mengembangkan klasifikasi varietas gandum berbasis pembelajaran mendalam difokuskan pada sejumlah kecil varietas gandum, dengan kumpulan data gambar yang lebih kecil yang tidak menangkap beberapa tampilan biji gandum. Gambar yang digunakan untuk model pelatihan biasanya diambil dari posisi yang seragam, yang membatasi kemampuan model untuk melakukan generalisasi di berbagai kondisi dunia nyata. Keterbatasan ini menghambat akurasi dan ketahanan model CNN untuk mengklasifikasikan berbagai varietas gandum saat menghadapi perubahan kecil pada gambar masukan. Penelitian saat ini bertujuan untuk mengatasi tantangan ini dengan memanfaatkan kumpulan data gambar gandum yang besar dan beragam yang terdiri dari 465.000 gambar yang mewakili 124 varietas gandum, masing-masing diambil dari 15 posisi berbeda. Tujuannya adalah untuk mengembangkan model klasifikasi berbasis CNN yang kuat yang dapat secara akurat mengklasifikasikan varietas gandum ke dalam 124 kelas yang berbeda, bahkan saat gambar diambil dari posisi yang berbeda. Selain itu, penelitian ini akan menilai efektivitas penggunaan pendekatan pembelajaran transfer bersama kumpulan data ini untuk lebih meningkatkan kinerja model. Melalui pendekatan ini, penelitian ini berupaya menunjukkan efektivitas penggunaan kumpulan data yang komprehensif dan sudut pandang gambar yang beragam dalam meningkatkan akurasi dan generalisasi model klasifikasi varietas gandum. Kontribusi penelitian ini dapat diringkas sebagai berikut:
- Pembuatan kumpulan data gambar besar melalui pengambilan gambar gandum dari 15 posisi berbeda.
- Pengembangan model klasifikasi berbasis CNN untuk mengklasifikasikan 124 varietas gandum.
- Demonstrasi efektivitas gambar multi-tampilan dalam meningkatkan kinerja model.
- Adopsi dan evaluasi teknik pembelajaran transfer dalam klasifikasi 124 varietas gandum.
- Penyediaan kumpulan data gambar besar untuk mendukung pekerjaan penelitian masa mendatang.
BAHAN DAN METODE
Sampel biji gandum dikumpulkan dari berbagai pusat penelitian di seluruh Turki, termasuk total 124 varietas gandum roti (Gbr. 1 ). Dalam penelitian ini, total 465.000 gambar diambil.

Akuisisi gambar
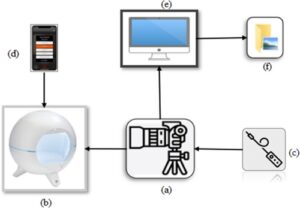
Gambar 124 varietas gandum diambil menggunakan kamera DS2000 beresolusi 24 MP (Canon, Tokyo, Jepang). Dengan memposisikan kamera pada jarak yang seragam, biji gandum ditempatkan di perangkat dengan meja putar yang dikenal sebagai Foldio360 ( https://orangemonkie.com ). Dengan kecepatan dan cahaya yang disesuaikan, gambar warna multi-tampilan diambil saat biji gandum diputar. Pengaturan ini membantu meningkatkan kumpulan data gambar baik dalam jumlah maupun variasi yang pada gilirannya memperkaya fitur representatif dan pada akhirnya meningkatkan efisiensi algoritma klasifikasi. Proses ini diselesaikan dengan menghubungkan pengaturan pengambilan Foldio360, kamera, kendali jarak jauh, telepon seluler, dan komputer (Gbr. 2 ). Meja putar Foldio360 dikontrol oleh aplikasi seluler untuk berputar 360° selama 1 menit. Saat gandum berputar, kamera diatur untuk mengambil lima gambar setiap 4 detik selama 1 menit. Dengan kata lain, gambar biji gandum diambil setiap 24° dari lima belas posisi, sehingga menghasilkan total 75 gambar setiap menit. Secara total, 465.000 gambar berhasil diambil.
Model Klasifikasi
CNN yang diusulkan
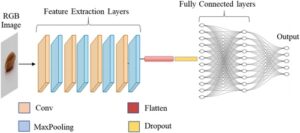
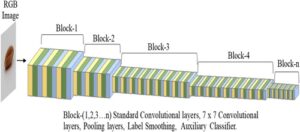
Dalam studi ini, model CNN yang relatif dangkal dengan 5,9 juta parameter yang dapat dilatih diimplementasikan. Model ini terdiri dari empat lapisan konvolusional, setiap lapisan menerapkan filter 3 × 3 untuk mengekstrak pola spasial dan fitur hierarkis. Fungsi aktivasi ReLU diterapkan setelah setiap lapisan konvolusional untuk memperkenalkan non-linearitas, yang memungkinkan jaringan untuk mempelajari representasi yang kompleks. Setiap lapisan konvolusional diikuti oleh lapisan max-pooling 2 × 2, yang mengurangi dimensi spasial sambil mempertahankan fitur-fitur penting. Lapisan perataan mengubah fitur yang diekstraksi menjadi vektor satu dimensi sebelum diteruskan ke lapisan yang terhubung penuh. Untuk mengurangi overfitting, lapisan dropout digunakan untuk menonaktifkan neuron secara acak selama pelatihan. Dua lapisan padat terakhir, masing-masing berisi 256 neuron, mengintegrasikan fitur yang diekstraksi dan mempelajari pola tingkat yang lebih tinggi. Akhirnya, fungsi aktivasi softmax digunakan dalam lapisan keluaran untuk menghitung probabilitas kelas di semua 124 varietas (kelas) (Gbr. 3 ). Model dilatih menggunakan penghentian awal dan panggilan balik titik pemeriksaan model, yang memantau hilangnya validasi.
Pembelajaran transfer
Transfer learning adalah pendekatan pembelajaran mesin di mana CNN yang dilatih untuk satu tugas digunakan kembali sebagai titik awal untuk model pada tugas kedua. 13 Alih-alih menginisialisasi bobot secara acak dan memulai pelatihan dari awal, bobot diinisialisasi menggunakan jaringan pra-terlatih yang dilatih pada set data berlabel besar, seperti set data gambar yang tersedia untuk umum. Dalam studi ini, kami fokus pada penggunaan model pra-terlatih yang dilatih pada set data skala besar seperti ImageNet dan kemudian mentransfer model ini ke tugas tertentu dengan memodifikasi lapisan yang terhubung penuh dan mengambil output dari set data target. Pembelajaran transfer banyak digunakan dalam aplikasi pertanian, seperti Gulzar et al . 14 menggunakan model populer untuk mengklasifikasikan varietas alfalfa. Studi ini bertujuan untuk memilih model yang mewakili keluarga arsitektur yang berbeda: model ringan (MobileNet) untuk efisiensi di lingkungan dengan sumber daya terbatas, arsitektur mendalam (DenseNet201) untuk memanfaatkan kedalaman untuk ekstraksi fitur dan model dengan komputasi paralel (InceptionV3) untuk menangkap fitur multi-skala secara efektif. Selain itu, dengan mempertimbangkan model seperti VGG16 dan VGG19, model dangkal dengan empat lapisan konvolusional dirancang dan dilatih dari awal sebagai alternatif representatif, seperti yang ditunjukkan pada Gambar 3 .
Jaringan Seluler
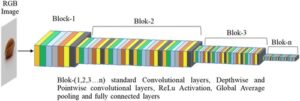
MobileNet adalah arsitektur CNN yang dikembangkan oleh Howard et al . 15 untuk aplikasi seluler dan tertanam. MobileNet dikenal karena penggunaan konvolusi yang dapat dipisahkan berdasarkan kedalaman sebagai blok penyusun utamanya, yang membedakannya dari lapisan konvolusional standar. Sebagai hasil dari desainnya yang ringan, MobileNet digunakan secara luas dalam aplikasi pertanian, seperti klasifikasi tanaman 16 – 19 dan deteksi penyakit. 20 – 22 Gambar 4 mengilustrasikan representasi MobileNet, tempat model dengan 12,9 juta parameter yang dapat dilatih diimplementasikan.
Jaringan Padat201
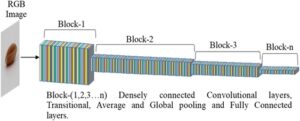
DenseNet adalah jaringan saraf yang dirancang untuk memastikan aliran informasi maksimum antar lapisan dengan menghubungkan setiap lapisan ke setiap lapisan lainnya secara feedforward. 23 Ini adalah arsitektur CNN yang telah mencapai hasil yang menjanjikan pada kumpulan data publik seperti ImageNet. Melalui pembelajaran transfer, berbagai arsitektur DenseNet telah diterapkan pada tugas-tugas di bidang pertanian, seperti klasifikasi dan pengenalan tanaman, 24 – 26 serta deteksi penyakit tanaman. 27 – 29 Gambar 5 mengilustrasikan keseluruhan arsitektur model DenseNet. Dalam studi ini, model DenseNet201 dengan 24,1 juta parameter yang dapat dilatih diadopsi.
Awal V3
Inception adalah arsitektur CNN yang dikembangkan oleh Szegedy et al . 30 Awalnya dirancang sebagai modul untuk arsitektur GoogLeNet, model ini banyak digunakan untuk deteksi objek dan analisis gambar. Inception dicirikan oleh modul inception-nya, yang melakukan beberapa konvolusi secara paralel. Model InceptionV3 yang diadopsi dalam studi ini dibedakan oleh fitur-fitur seperti faktorisasi konvolusi 7 × 7, penghalusan label, dan penggunaan pengklasifikasi tambahan untuk menyebarkan informasi label ke lapisan jaringan yang lebih rendah. InceptionV3 telah berhasil dan banyak digunakan dalam pertanian untuk tugas-tugas seperti deteksi penyakit, 31 – 33 pengenalan dan klasifikasi spesies dan varietas, 34 – 37 dan klasifikasi hama dan gulma. 38 , 39 Gambar 6 mengilustrasikan representasi dasar InceptionV3. Model InceptionV3 yang digunakan dalam studi ini memiliki 18,9 juta parameter yang dapat dilatih.
Paket dataset dan pelatihan
Data dibagi menjadi set pelatihan (80%), validasi (10%) dan pengujian (10%). Semua model dilatih selama 100 periode pada saat yang sama dengan penerapan titik pemeriksaan model dan penghentian awal panggilan balik untuk mencegah overfitting. Gambar 7 menunjukkan keseluruhan proses dan metode pelatihan.
Pelatihan model CNN dilakukan pada server e-Infrastruktur Sains Nasional Turki (TRUBA) di klaster Akya-Cuda karena melibatkan kumpulan data yang besar. Klaster tersebut berisi 24 server Supermicro 1029GQ-TRT. Setiap server dilengkapi dengan dua prosesor Intel Xeon Scalable Gold 6148, yang menyediakan total 40 inti prosesor per server dengan kecepatan pemrosesan 2,4 GHz. Setiap server terdiri dari empat kartu GPU Nvidia Tesla V100, masing-masing dengan memori HBM 16 GB. Dalam pelatihan tersebut, digunakan pustaka pembelajaran mesin dan penanganan data Python Keras dan Tensorflow.
Metrik kinerja
Metrik kinerja, yaitu akurasi, presisi, recall, dan skor F1, digunakan untuk mengevaluasi keberhasilan klasifikasi model pada set data uji. Metrik kinerja model, dihitung berdasarkan True Positives (TP), True Negatives (TN), False Positives (FP), dan False Negatives (FN), digunakan untuk menilai kinerja keempat model [Persamaan (1) hingga (4)].

HASIL
Model CNN yang diusulkan
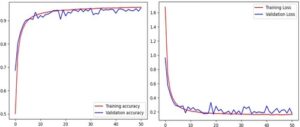
Model CNN dangkal yang diusulkan, yang memiliki empat lapisan konvolusional dan empat lapisan max-pooling, dilatih menggunakan 5% dropout, dengan 100 epoch, ukuran batch 32 dan pengoptimal ‘adam’, memanfaatkan dan mekanisme penghentian awal dengan nilai kesabaran 20 epoch sebagai titik pemeriksaan model. Secara total, 465.000 gambar dibagi menjadi 80% pelatihan, 10% validasi dan 10% set data pengujian. Semua kelas berisi jumlah gambar yang kira-kira sama, memastikan representasi kelas yang seimbang dan mencegah underrepresentasi. Seperti yang ditunjukkan dalam kurva akurasi pelatihan dan validasi, kedua akurasi meningkat secara signifikan selama 10 epoch pertama dan mulai stabil saat pelatihan berlangsung (Gbr. 8 ). Kedekatan akurasi pelatihan dan validasi menunjukkan risiko overfitting yang sangat rendah. Meskipun ada fluktuasi dalam kurva validasi, kedekatannya dengan kurva pelatihan menunjukkan bahwa model tersebut berkinerja baik pada set validasi. Pelatihan berhenti pada epoch 51, model terbaik tercatat pada epoch 31, mencapai akurasi 94,03% ketika akurasi validasi tidak menunjukkan peningkatan selama 20 epoch berturut-turut. Dengan demikian, dalam hal metrik kinerja yang disediakan dalam Tabel 1 , akurasi, presisi, recall dan skor F1 ditetapkan masing-masing sebesar 95,40%, 95,44%, 95,39% dan 95,36%. Nilai-nilai metrik ini menunjukkan kinerja klasifikasi model yang tinggi. Tingkat akurasi yang tinggi sebesar 95,40% menyoroti kemampuan model untuk membuat klasifikasi yang benar secara keseluruhan. Selain itu, nilai-nilai presisi dan recall yang dekat menunjukkan kinerja yang seimbang, dengan tingkat positif palsu dan negatif palsu yang rendah. Skor F1 yang tinggi, sejalan dengan nilai-nilai ini, mengonfirmasi kinerja keseluruhan model yang kuat dan keandalannya dalam menghasilkan hasil yang akurat untuk tugas-tugas klasifikasi. Model yang baru diusulkan secara umum berkinerja baik; namun, berbagai kelas rentan terhadap kesalahan klasifikasi yang signifikan. Varietas Eylül menunjukkan nilai ingatan terendah sebesar 0,824, dengan jumlah kesalahan klasifikasi tertinggi sebanyak 69. Sebagian besar kesalahan ini melibatkan kebingungan dengan kelas-kelas seperti Abide di mana sembilan contoh salah diklasifikasikan, dan Damla dan Harman22, di mana masing-masing 11 contoh termasuk di antara kesalahan prediksi tertinggi, yang menunjukkan kesulitan dalam membedakan Eylül. Rincian lebih lanjut tentang klasifikasi diberikan dalam Informasi pendukung (Data S1 , Matriks Kebingungan CNN yang Diusulkan).
| Model | Parameter yang dapat dilatih | Metrik (%) | |||
|---|---|---|---|---|---|
| Ketepatan | Presisi | Mengingat | Skor F1 | ||
| CNN yang diusulkan | 5 876 540 | 95.40 | 95.44 | 95.39 | 95.36 |
| Jaringan Seluler | 12 894 204 | 90.54 | 91.02 | 90.39 | 90.44 |
| Jaringan Padat201 | Nomor telepon 24 133 628 | 92.41 | 92.88 | 92.26 | 92.32 |
| Awal V3 | Nomor telepon 18 923 516 | 83.47 | 84.11 | 83.24 | 83.25 |
Jaringan Seluler
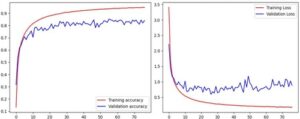
Dengan menggunakan arsitektur MobileNet CNN, pembelajaran transfer diterapkan dengan memodifikasi hanya lapisan yang terhubung penuh dan menambahkan dua lapisan tersembunyi yang masing-masing berisi 256 dan 128 neuron. Semua parameter pelatihan tetap serupa dengan model CNN yang diusulkan. Kurva pembelajaran yang ditunjukkan pada Gambar 9 menunjukkan bahwa akurasi pelatihan meningkat secara stabil, khususnya setelah epoch ke-10. Pola yang sama, dengan fluktuasi kecil, juga diamati pada kurva validasi. Pelatihan berhenti pada epoch ke-69, dengan model terbaik tercatat pada epoch ke-39. Akurasi pelatihan dan validasi untuk model ini masing-masing adalah 96,62% dan 91,49%, sedangkan akurasi pengujian keseluruhan ditetapkan sebesar 90,54%. Sedikit perbedaan antara akurasi pelatihan dan validasi menunjukkan sedikit overfitting dalam model. Selain itu, metrik kinerja (yaitu akurasi, presisi, recall dan skor F1) ditemukan masing-masing sebesar 90,54%, 91,02%, 90,39% dan 90,44%, seperti yang ditunjukkan pada Tabel 1. Nilai-nilai ini menunjukkan kinerja keseluruhan model yang tinggi. Tingkat akurasi 90,54% menyoroti kemampuan model yang kuat untuk membuat klasifikasi yang benar. Kedekatan nilai presisi dan recall menunjukkan bahwa model menyeimbangkan tingkat positif palsu dan negatif palsu secara efektif, meminimalkan kedua jenis kesalahan. Skor F1 sebesar 90,44%, yang selaras dengan nilai-nilai ini, mengonfirmasi kinerja keseluruhan model yang konsisten dan andal. Hasil-hasil ini menunjukkan bahwa model tersebut efektif untuk tugas-tugas klasifikasi dan dapat digunakan secara efisien dalam aplikasi semacam itu. Mengenai analisis kesalahan klasifikasi, kelas Kayra menunjukkan recall terendah (0,712), dengan 108 kesalahan klasifikasi. Sejumlah besar kesalahan ini melibatkan kebingungan dengan varietas yang serupa, seperti Aytenabla (34 kesalahan klasifikasi), Demirhan (23 kesalahan klasifikasi), dan Hamitbey (18 kesalahan klasifikasi), di antara yang lain sebagaimana disediakan dalam Informasi pendukung (Data S2 , MobileNet-Confusion Matrix). Kesalahan klasifikasi ini menunjukkan bahwa model tersebut kesulitan membedakan Kayra dari kelas-kelas yang tampak serupa ini, yang mengakibatkan rendahnya daya ingat Kayra.
Jaringan Padat201
Strategi serupa diadopsi untuk DenseNet201, salah satu arsitektur CNN yang populer. Model dilatih selama 35 epoch, dengan model terbaik tercatat pada epoch ke-15. Kurva pembelajaran, seperti yang ditunjukkan pada Gambar 10 , menunjukkan bahwa akurasi pelatihan dan validasi meningkat dengan mantap hingga sekitar epoch ke-20. Namun, setelah titik ini, ada peningkatan dalam kerugian pelatihan dan validasi atau penurunan akurasi validasi, yang menunjukkan potensi risiko overfitting. Meskipun demikian, mekanisme penghentian awal memastikan bahwa model disimpan sebelum ini terjadi, menjaga kurva akurasi validasi tetap stabil. Perbedaan antara akurasi pelatihan dan validasi relatif lebih kecil daripada yang diamati di MobileNet. Metrik kinerja (yaitu akurasi, presisi, recall dan skor F1) dihitung masing-masing sebesar 92,41%, 92,88%, 92,26% dan 92,32%, seperti yang disajikan dalam Tabel 1. Hasil-hasil ini menunjukkan bahwa model mencapai kinerja klasifikasi yang tinggi dan seimbang. Tingkat akurasi sebesar 92,41% menekankan kapasitas model yang kuat untuk membuat klasifikasi yang benar. Nilai presisi dan recall yang mendekati menunjukkan bahwa model tersebut secara efektif menyeimbangkan rasio positif palsu dan negatif palsu. Selain itu, skor F1 sebesar 92,32% semakin menegaskan kinerja keseluruhan model yang kuat, yang menunjukkan kemampuannya untuk menghasilkan hasil yang konsisten dalam tugas klasifikasi. Temuan ini menyoroti keandalan dan efektivitas model untuk digunakan dalam aplikasi klasifikasi. Saat menganalisis kesalahan klasifikasi, kelas Kilistra menunjukkan recall terendah (0,7510), dengan 74 kesalahan prediksi. Dari 74 kesalahan klasifikasi, 23 contoh diprediksi secara salah sebagai Ikonya, 13 Ozcan (Data S3 , DenseNet201-Confusion Matrix). Pola ini menunjukkan bahwa Kilistra memiliki fitur visual yang substansial yang menghadirkan tantangan potensial.
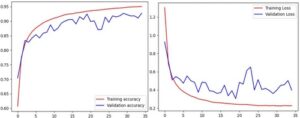
Awal V3
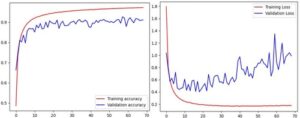
Model InceptionV3 dievaluasi menggunakan metodologi yang sama yang digunakan untuk melatih DenseNet201 dan MobileNet. Model dilatih hingga epoch 77, dengan penghentian awal berdasarkan kriteria kesabaran 20 epoch. Gambar 11 mengilustrasikan akurasi pelatihan dan validasi selama proses pelatihan. Selama epoch awal, model menunjukkan pembelajaran cepat, dengan akurasi pelatihan terus meningkat sebelum mencapai titik puncak sekitar 90%. Akurasi validasi, meskipun agak berfluktuasi, secara bertahap membaik dan stabil pada sekitar 83% setelah sekitar 40 epoch. Model mencapai akurasi validasi akhir sebesar 83,37% dan akurasi pengujian yang sesuai sebesar 83,47%. Nilai dekat dari akurasi pengujian dan validasi menyoroti kemampuan generalisasi model. Metrik kinerja (yaitu akurasi, presisi, recall dan skor F1) dihitung masing-masing sebesar 83,47%, 84,11%, 83,24% dan 83,25%, seperti yang ditunjukkan pada Tabel 1 . Hasil-hasil ini menunjukkan bahwa kinerja klasifikasi model cukup baik. Tingkat akurasi sebesar 83,47% menunjukkan akurasi model yang baik, meskipun hal itu menunjukkan ruang untuk perbaikan guna mencapai tingkat kinerja yang lebih tinggi. Kedekatan nilai presisi dan recall menunjukkan bahwa model secara efektif menyeimbangkan rasio positif palsu dan negatif palsu. Skor F1 sebesar 83,25% selaras dengan metrik-metrik ini, yang mencerminkan kinerja keseluruhan model yang konsisten dan seimbang. Sementara metrik-metrik ini memuaskan, hasilnya juga menunjukkan bahwa optimasi lebih lanjut mungkin diperlukan untuk meningkatkan kinerja model dan mencapai efektivitas klasifikasi yang lebih tinggi. Memeriksa kesalahan klasifikasi, kelas Mesut, yang memiliki recall terendah sebesar 0,4583 menghasilkan total 117 kesalahan klasifikasi, 30 contoh salah diklasifikasikan sebagai Bezostaja1, 21 sebagai Reis, 20 sebagai Nacibey dan 18 sebagai Mufitbey, antara lain sebagaimana diberikan dalam Informasi pendukung (Data S4 , InceptionV3-Confusion Matrix). Hal ini menunjukkan bahwa Mesut memiliki karakteristik visual utama yang sama dengan varietas ini, yang sulit dibedakan secara akurat oleh model. Rendahnya daya ingat yang diamati dalam kelas khusus ini menunjukkan bahwa, meskipun model tersebut berkinerja cukup baik secara keseluruhan, model tersebut menghadapi kesulitan yang cukup besar dalam mengidentifikasi Mesut dengan benar, yang menyebabkan tingkat negatif palsu yang lebih tinggi.
DISKUSI
Zhou et al . 40 melakukan studi tentang identifikasi varietas biji gandum menggunakan kumpulan data spektral inframerah dekat (NIR) besar yang terdiri atas lebih dari 140.000 biji gandum dari 30 varietas. Mereka mengusulkan pemilih fitur berbasis CNN (CNN-FS) baru untuk mengidentifikasi saluran spektral terkait target. Kerangka kerja CNN dengan perhatian (CNN-ATT) dirancang untuk klasifikasi data satu dimensi. CNN-ATT mencapai akurasi 93,01% menggunakan spektrum penuh dan 90,20% saat dilatih pada fitur 60 saluran yang diperoleh melalui metode CNN-FS. Laabassi et al . 41 menggunakan pembelajaran transfer untuk mengklasifikasikan empat varietas gandum, mencapai akurasi 98,1% dan 98,3% dengan model MobileNet dan DenseNet201, masing-masing. Demikian pula, Taner et al . 42 merancang model CNN baru dan dangkal yang terdiri dari empat lapisan konvolusional untuk klasifikasi 17 varietas hazelnut, melampaui model yang telah dilatih sebelumnya dengan akurasi keseluruhan sebesar 98,63%.
Dalam studi terkait CNN dan fitur mendalam, Çelik et al . 43 memperkenalkan model CNN hibrida untuk mengidentifikasi 41 butir gandum durum. Dengan menggabungkan lapisan fitur Logits dan Pool10 dari model CNN MobileNetV2 dan SqueezeNet, fitur mendalam baru digunakan untuk melatih mesin vektor pendukung (SVM). Eksperimen mereka menggunakan model hibrida mencapai akurasi uji 91,89%. Dalam penelitian mereka, Lingwal et al . 43 mengembangkan model baru menggunakan CNN untuk mengklasifikasikan 15 varietas gandum berbeda berdasarkan gambar sifat visualnya. Model dilatih pada kumpulan data yang berisi 15.000 gambar butir gandum, dan berbagai hiperparameter dioptimalkan untuk membuat model yang paling akurat dan efisien untuk klasifikasi. Kinerja model yang berbeda dibandingkan menggunakan akurasi klasifikasi dan kehilangan entropi silang kategoris. Model dengan kinerja terbaik mencapai akurasi pelatihan sebesar 94,88% dan akurasi uji sebesar 97,53%, yang menunjukkan klasifikasi varietas gandum yang berhasil dan tepat menggunakan CNN berdasarkan sifat visual. Untuk mengklasifikasikan lebih dari 40 kultivar gandum, Işık et al . 44 mengembangkan dua metode menggunakan pencitraan cahaya tampak (VL), inframerah dekat tampak (VNIR) dan inframerah gelombang pendek (SWIR). Teknik-teknik ini menggunakan algoritma ekstraksi fitur tradisional dan modern, yaitu kerangka bag of words (BoW) dan kerangka CNN. Aturan konsensus ditetapkan dengan menggabungkan prediksi dari kerangka CNN dan BoW untuk mengidentifikasi kultivar gandum. Hasilnya menunjukkan akurasi tinggi dengan 99,94% untuk kerangka CNN dan 68,94% untuk kerangka BoW. Eksperimen penelitian mengungkapkan bahwa fitur CNN mengungguli fitur buatan tangan dalam merepresentasikan dan mencocokkan pola tekstur secara akurat, terutama dalam kasus biji gandum berulang dalam gambar, membuat CNN lebih cocok untuk klasifikasi kultivar gandum. Que et al . 45 menggunakan interval fitur spektral terpilih yang digabungkan dengan CNN yang dikelompokkan untuk mengidentifikasi delapan varietas benih. Mereka melaporkan bahwa, di antara metode pemilihan interval, penghapusan kontinum interval yang dikombinasikan dengan CNN menghasilkan peningkatan klasifikasi sebesar 4,4%.
Baru-baru ini, Yasar et al . 46 mengadopsi strategi pembelajaran transfer untuk mengklasifikasikan lima varietas gandum. Setelah mengekstraksi fitur mendalam menggunakan arsitektur Xception, mereka melatih jaringan saraf BiLSTM dan mencapai akurasi 97,73%. Setelah membuat gambar gandum dengan bantuan reflektansi spektrometer. Dengan cara yang sama, Yasar et al . 47 menyelidiki integrasi CNN ResNet yang telah dilatih sebelumnya dan SVM dari model pembelajaran tradisional untuk mengklasifikasikan lima varietas gandum roti. Studi ini melaporkan akurasi klasifikasi sebesar 94,51% menggunakan seribu fitur yang paling efektif. Ceyhan et al . 48 melatih model pembelajaran mendalam untuk mengklasifikasikan dua puluh delapan varietas gandum dan kinerja klasifikasi adalah 99,52%. Han et al . 49 melaporkan bahwa pencitraan hiperspektral yang dikombinasikan dengan fusi fitur pembelajaran mendalam saluran ganda menghasilkan akurasi sebesar 99,18%, 97,30%, dan 93,18% untuk kombinasi gandum tiga varietas, empat varietas, dan lima varietas, sehingga menghadirkan teknik baru untuk identifikasi varietas.
Dalam studi saat ini, hasil berdasarkan CNN dangkal dan pembelajaran transfer dengan model MobileNet, DenseNet201 dan InceptionV3 dianalisis, dan mencapai akurasi pengujian yang menjanjikan sebesar 95,40%, 90,54%, 92,41% dan 83,47%. Model CNN yang diusulkan mengungguli arsitektur populer dengan akurasi pengujian keseluruhan sebesar 95,40%. DenseNet201 dirancang untuk memaksimalkan pemanfaatan fitur dengan menghubungkan setiap lapisan ke semua lapisan berikutnya melalui pengumpanan maju. Konektivitas padat ini penting untuk menangkap pola kompleks dalam data, terutama dalam kasus dengan perbedaan kecil di antara sejumlah besar kelas, seperti 124 varietas gandum. Kemampuan representasi fitur mendalam dari DenseNet201 memainkan peran penting dalam mencapai akurasi pengujian sebesar 92,41%. MobileNet secara umum dianggap sebagai model yang lebih ringan dan memiliki jumlah parameter yang dapat dilatih yang sebanding dengan DenseNet201. Efisiensi yang dioptimalkan memungkinkan penggunaannya tanpa kehilangan akurasi yang signifikan. Dengan menggunakan konvolusi yang dapat dipisahkan berdasarkan kedalaman untuk menangkap fitur-fitur yang relevan secara efektif, MobileNet mencapai akurasi sebesar 90,54%, mengungguli DenseNet201 dan InceptionV3 dengan jumlah parameter yang lebih sedikit. Arsitektur InceptionV3, dalam hal parameter yang dapat dilatih, lebih besar dari MobileNet tetapi lebih kecil dari DenseNet201. Arsitektur ini dapat menangkap berbagai tingkat abstraksi dalam gambar dengan menggunakan beberapa filter konvolusi dengan berbagai ukuran secara paralel. Meskipun InceptionV3 mencapai akurasi terendah di antara ketiga model yang telah dilatih sebelumnya sebesar 83,47%, desainnya masih menawarkan keunggulan dalam menangkap berbagai fitur dan melakukan generalisasi ke data yang tidak terlihat, yang sangat penting untuk membedakan di antara sejumlah besar kelas.
Model CNN yang diusulkan menguntungkan karena lebih ringan dan menunjukkan kinerja terbaik dibandingkan dengan model lain. Ketika membandingkan ukuran parameter yang dapat dilatih, diamati bahwa model CNN yang diusulkan, dengan 5,9 juta parameter yang dapat dilatih, dua hingga tiga kali lebih sedikit daripada model pembelajaran transfer. Lebih jauh lagi, untuk mengatasi kendala komputasional potensial, analisis trade-off dilakukan antara kompleksitas model (diukur dengan ukuran model dan waktu pelatihan) dan kecepatan inferensi (Tabel 2 ). Dari model-model tersebut, CNN yang diusulkan, MobileNet, DenseNet201 dan InceptionV3, model yang baru diusulkan muncul sebagai pilihan yang paling seimbang, mencapai akurasi tertinggi (95,40%) dengan kecepatan inferensi tercepat (6,02 ms) dan ukuran model terkecil (67,3 MB). Meskipun DenseNet201 memberikan akurasi yang kompetitif (92,41%), hal itu mengorbankan ukuran model yang jauh lebih besar (347 MB) dan kecepatan inferensi yang lebih lambat (25,7 ms). Sebaliknya, MobileNet menawarkan alternatif yang ringan dengan kecepatan inferensi yang baik (6,9 ms) dan akurasi yang wajar (90,54%), sehingga cocok untuk lingkungan dengan keterbatasan sumber daya seperti perangkat seluler atau edge. Berdasarkan analisis ini, model empat lapis dapat dianggap sangat direkomendasikan untuk penerapan ketika efisiensi komputasi dan kinerja tinggi sangat penting. Ini menunjukkan bahwa, meskipun pembelajaran transfer sering kali memberikan titik awal yang baik, pembelajaran ini mungkin tidak selalu menghasilkan hasil terbaik ketika masalah target berbeda secara signifikan dari tugas-tugas yang menjadi dasar pelatihan model asli. Untuk masalah khusus ini, arsitektur yang lebih sederhana mungkin lebih efektif daripada jaringan yang lebih besar dan lebih kompleks. Namun, pada titik ini, perlu dicatat bahwa, meskipun waktu inferensi yang dilaporkan diukur pada perangkat keras berkinerja tinggi, kami mengakui bahwa ini tidak secara langsung mencerminkan kinerja dunia nyata pada perangkat seluler atau edge. Meskipun demikian, fitur (kecepatan inferensi dan ukuran model) dari model CNN yang baru diusulkan merupakan indikator kuat potensinya untuk penerapan di lingkungan dengan keterbatasan sumber daya. Dalam praktiknya, waktu inferensi pada perangkat seluler mungkin lebih tinggi akibat keterbatasan kapasitas komputasi, tetapi model ringan seperti CNN yang diusulkan tetap dapat mempertahankan kinerja interaktif, khususnya bila digabungkan dengan teknik pengoptimalan seperti konversi TensorFlow Lite. Pekerjaan selanjutnya mencakup pembuatan profil waktu inferensi pada perangkat keras seluler aktual untuk memvalidasi kesesuaiannya untuk klasifikasi di lapangan.
| Model | Waktu pelatihan | Kecepatan inferensi (ms) | Akurasi (%) | Ukuran model (MB) |
|---|---|---|---|---|
| CNN yang diusulkan | 80 jam 32 menit 4 detik | 6.02 | 95.4 | 67.3 |
| Jaringan Seluler | 67 jam 35 menit 23 detik | 6.9 | 90.54 | 160 |
| Jaringan Padat201 | 99 jam 28 menit 46 detik | 25.7 | 92.41 | 347 |
| Awal V3 | 116 jam 19 menit 54 detik | 11.4 | 83.47 | 300 |
Lebih jauh lagi, kumpulan data citra multi-tampilan yang digunakan dalam studi ini memberikan kontribusi yang signifikan terhadap keberhasilan model, karena menyediakan representasi yang lebih kaya dan lebih beragam dari 124 varietas gandum, yang pada gilirannya meningkatkan kekokohan model. Temuan-temuan ini, yang didukung oleh literatur yang relevan, menekankan pentingnya mempertimbangkan arsitektur CNN kustom, daripada hanya mengandalkan model yang telah dilatih sebelumnya, terutama ketika berhadapan dengan tugas-tugas klasifikasi yang kompleks. Berdasarkan kesimpulan yang disebutkan di atas dan didukung oleh literatur yang relevan, jelas bahwa, terlepas dari tantangan yang terkait dengan sumber daya komputasi yang tinggi, keuntungan dari model CNN kustom lebih besar daripada kerugiannya. Model CNN yang diusulkan dengan kumpulan data citra multi-tampilan memberikan kontribusi terhadap keberhasilan keseluruhan model dalam tugas yang menantang, seperti mengklasifikasikan 124 varietas gandum, dengan menyediakan representasi kelas yang lebih kaya dan lebih beragam, yang pada akhirnya meningkatkan kekokohan model. Tabel 3 menyajikan daftar karya penelitian yang relevan.
| Jumlah varietas | Fitur | Model dan akurasi | Referensi |
|---|---|---|---|
| 30 | Data spektral NIR | CNN: 93,01% | 40 |
| 50 | Fitur mendalam | Kapasitas Penyimpanan Data: 99,0% | 50 |
| 41 | Fitur mendalam | Kapasitas Penyimpanan Data: 91,89% | 43 |
| 15 | Gambar RGB | CNN: 97,52% | 51 |
| 40 | Gambar VL, VNIR, dan SWIR | CNN: 99,94% | 44 |
| 4 | Fitur mendalam | Kapasitas Penyimpanan Data: 99,91% | 50 |
| 5 | Fitur mendalam | Indeks BiLSTM: 97,73% | 46 |
| 24 | Refleksi spektrometer | CNN: 99,52% | 48 |
| 12 | Spektroskopi Terahertz | CNN: 97,8% | 24 |
| 124 | Gambar RGB | CNN: 95,40% | Model yang diusulkan 52 |
KESIMPULAN
Pengenalan luas pendekatan pemuliaan gandum modern telah meningkatkan pemilihan dan pemuliaan varietas gandum baru. Identifikasi manual varietas yang sangat mirip sulit, tidak konsisten, dan kurang efektif karena bergantung pada keterampilan manusia. Untuk mengatasi masalah ini, teknologi baru dan inovatif seperti visi komputer telah muncul untuk membantu industri dan laboratorium dalam mengganti operasi manual dengan sistem otomatis yang mengendalikan proses pada efisiensi optimal. Dalam studi saat ini, arsitektur pra-terlatih populer seperti MobileNet, DenseNet201, dan InceptionV3 digunakan bersama model CNN untuk mengklasifikasikan 124 varietas gandum. Model dilatih selama 100 epoch menggunakan hiperparameter serupa dengan kumpulan data besar yang terdiri dari sekitar 465.000 gambar. Untuk memastikan pelatihan model yang efisien dan mencegah risiko overfitting, titik pemeriksaan model dan panggilan balik penghentian awal digunakan. Di antara model-model tersebut, model CNN yang diusulkan, DenseNet201, MobileNet dan InceptionV3 mencapai akurasi klasifikasi masing-masing sebesar 95,40%, 92,41%, 90,54% dan 83,47%. Dapat disimpulkan bahwa kumpulan data besar yang diambil dari berbagai posisi memainkan peran penting dalam kinerja yang lebih tinggi dari model-model ini karena memungkinkan model untuk menggeneralisasi lebih efektif dan beradaptasi dengan kondisi dunia nyata, yang secara signifikan berkontribusi pada akurasi klasifikasi tinggi yang dicapai. Akhirnya, studi ini merekomendasikan peningkatan kedalaman lapisan dan penyempurnaan hiperparameter seperti ukuran neuron, laju pembelajaran, ukuran batch dan tingkat putus sekolah untuk meningkatkan akurasi model CNN yang diusulkan dan mengidentifikasi konfigurasi yang optimal. Dalam pendekatan pembelajaran transfer, pengujian model populer tambahan harus dilakukan. Lebih jauh, direkomendasikan untuk menyempurnakan model dengan membekukan lapisan awal tertentu pada saat yang sama dengan memungkinkan lapisan selanjutnya beradaptasi dengan kumpulan data tertentu, sehingga memaksimalkan akurasi klasifikasi. Lebih jauh lagi, mengingat kemajuan terkini dalam pembelajaran mendalam, penelitian di masa mendatang didorong untuk mengeksplorasi teknik pembelajaran mandiri, yang dapat berkontribusi pada peningkatan kinerja model. Selain itu, menggabungkan mekanisme perhatian ke dalam arsitektur CNN dapat meningkatkan fokus fitur dan meningkatkan keterpisahan antarkelas, khususnya di antara varietas gandum yang secara visual serupa. Selain itu, kumpulan data gambar besar ini akan tersedia untuk umum sebagai bank data untuk penelitian lebih lanjut, untuk memungkinkan peneliti lain mengembangkan karya ini dan mengeksplorasi metodologi baru untuk klasifikasi varietas gandum.

